(one of the InLOC Bindings)
The InLOC RDF Binding
- 1 Introduction
- 1.1 Conventions for RDF graph diagrams in this document
- 1.2 Representing the information model in RDF
- 1.3 Naturalized RDF
- 2 LOC structures and definitions
- 2.1 Turtle preamble with prefixes
- 2.2 A LOC structure with its direct properties
- 2.3 LOC definitions
- 2.4 Graph for LOC structure and definitions
- 3 LOC associations
- 3.1 A "by" association
- 3.2 A "LOCrel" association with no number
- 3.3 A "LOCrel" association with a number
- 3.4 Some "category" associations
- 3.5 A "credit" association
- 3.6 A "level" association
- 3.7 A "topic" association
- 3.8 Graph for LOC associations
- 4 Other considerations
- 4.1 Sub-structures
- 4.2 Other information that could be added in RDF
- 4.3 Variant predicate IRIs
- 4.4 Unexpected literal values
- 5 Use of the naturalized RDF binding
- 5.1 RDFS ontology for naturalized RDF binding
- 5.2 How to convert InLOC naturalized RDF triples to XML
- 6 Further reading
Introduction
For an introduction to RDF, there are several well-known sources, including:
- The official pages from the W3C
- Resource Description Framework on Wikipedia
As explained in the Wikipedia article, "RDF is an abstract model with several serialization formats". But because they all conform to the same underlying model, they are all in principle inter-convertible. Of particular interest for this documentation are:
- Turtle, particularly for the prefix conventions, to make the examples as easy to read as possible;
- N-Triples, one of the simplest formats, which could be used for the most straightforward processing. See this section on N-Triples from RDF test cases.
Over recent years, the term "URI" standing for "uniform resource identifier" has gradually migrated to "IRI", standing for "internationalized resource identifier", in contexts where the ability to use extensive character sets would be useful, as it is here. Therefore, the term "IRI" is used in preference in this binding. "IRI references", that is, IRIs, enclosed between < and > characters, are used in Turtle and N-Triples to identify "resources". This is not the place to discuss what a resource might be in general, but for InLOC purposes, it is definitions or descriptions of concepts of ability, competence, knowledge, level, skill, etc., and documents and structures containing these, that are the "resources" of primary interest.
The example given here initially corresponds to the Vitae Researcher Development Framework worked example. To distinguish the two "RDF"s, Vitae's one will here be abbreviated either VitaeRDF or VRDF. Plain "RDF" will mean the Resource Description Framework. The example is taken from published materials, but is not yet endorsed by Vitae, the owner of the Researcher Development Framework. In particular, the allocation of the VRDF prefix is entirely provisional and unofficial.
This InLOC documentation now gives graphical representations, as are commonly used when explaining RDF, Linked Data, and the Semantic Web (as for example in the RDF Primer).
The main binding requirement from the stakeholders known to the project was XML, rather than RDF. To naturalize an information model for XML is rather different than to naturalize it for RDF, and the InLOC information model is naturalized primarily for XML.
The InLOC information model uses the LOCassociation structure in a way not unlike an RDF triple, but it is not structured in exactly the same way as a triple in RDF/XML. To use the full power of RDF and associated technologies such as SPARQL and OWL, specific kinds of LOC association should be represented as actual triples. This results in a more compact representation, more natural for RDF in a Semantic Web context.
Conventions for RDF graph diagrams in this document
The original InLOC information model is shown elsewhere in the form of a UML diagram, and in a different way in the InLOC information model diagram. As RDF is composed of triples, the model diagrams here are adapted to show either the form of triples, or the actual triples. Each triple is composed of a subject, a predicate and an object.
- The subject of the triple is a resource shown as an oval at the start of a directed arc.
- Predicates are represented by the labels in the middle of arcs, shown here as green rectangles.
- The object is the resource or literal at the end of an arc:
- an oval object represents a resource;
- a rectangular object represents a literal.
- Most of the colours are borrowed from the same information model diagram in the Guidelines.
Representing the information model in RDF
The InLOC information model was initially developed with an XML binding in mind. Translating this to RDF would result in something like Figure 1. Here, arrow heads are put only on the second part of the arc, joining the predicate to the object. The arrow head is by the object.
However, note that this representation is NOT USED for the InLOC RDF binding.
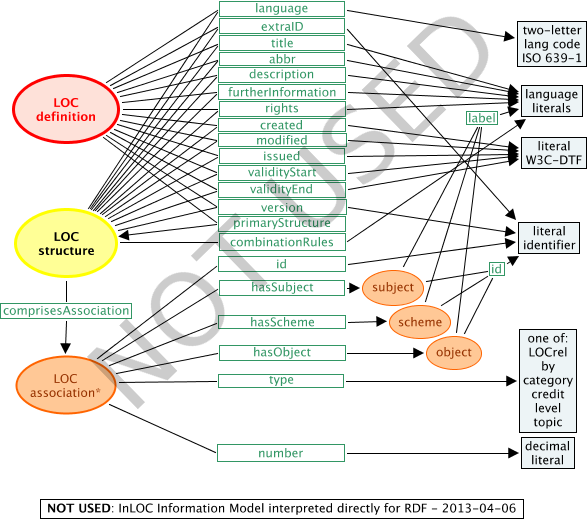
Figure 1: the original InLOC information model interpreted for RDF, but NOT USED
This compares easily to that information model diagram in the Guidelines section on InLOC explained through example. One important difference is that, in RDF, the identifier of the resources is the IRI that stands for the subject, predicate or object. This means that normally, as long as the identifier is an IRI, it does not need to appear separately in the RDF model.
For RDF to follow the original information model, it needs predicates that have been defined in the information model, but were not used in the XML binding (as they were not necessary). Very similarly to the XML binding, both LOC structures and LOC definitions are the subject of several straightforward triples expressing many of their direct properties. However, there is no explicit "id" triple for LOC structures or definitions, because the IRI that was the id attribute in the XML binding stands as the subject or object of the triple itself. The language is represented by the same code, but a default language for a LOC structure needs to be given its own triple with the language predicate. Literals that can appear in several language versions have different languages distinguished by a language tag appended to the string, in place of XML's xml:lang attribute.
To avoid the need to nest XML, LOC structures contain LOC associations, which express the relationships and compound properties of both LOC structures and definitions. Thus, for a corresponding RDF representation, LOC structures would become the subject of triples with the predicate "comprisesAssociation" (not used in the XML binding), where the object is each contained LOCassociation. LOCassociations in turn would have three predicates "hasSubject", "hasScheme" and "hasObject", not used as XML element names, having the subject, scheme and object as their respective objects. LOCassociation, subject, scheme and object are never required to be referred to from outside the particular LOCstructure that is being represented.
Though this structure is neat, it is not as one would expect of an RDF model for Linked Data or the Semantic Web. The relationships between LOC structures and definitions are represented only through being the literal identifiers that are the object of triples with "id" predicates. It is not easy to use these in queries, as the linked data is linked only indirectly. Therefore, this approach is NOT USED for the InLOC RDF binding, but instead an alternative approach is followed, as follows.
Naturalized RDF
For a more natural RDF approach, just a few aspects of the model need to be slightly rearranged. The direct properties from language to combinationRules are still represented in exactly the same way as for the version following the original information model in Figure 1. But the role of the LOC association changes. There is no nesting in any case in Turtle or N-Triples, and so no need to avoid it. Instead, the LOC structure or definition, as appropriate, can become the subject of any triples referring to it, so the subject is no longer given within a LOCassociation.
Following this approach, the main change from Figure 1 to 2 is that instead of the uniform LOCassociation construct, relationships and compound properties are treated differently. For relationships of LOC structures and definitions, triples can be used in a completely natural way. For compound properties of type by, the scheme id also becomes the predicate of the triple, so there is no need for a separate scheme; the object becomes the RDF object of the triple. For the other kinds of compound property, triples are constructed with the subject as either a LOC structure or definition, and an "association resource" as object, which could be a RDF blank node. Further triples link this association resource to the scheme and the object, just as they appear in the original information model.
Figure 2 below shows how the RDF is changed to naturalize it for Linked Data and the Semantic Web.
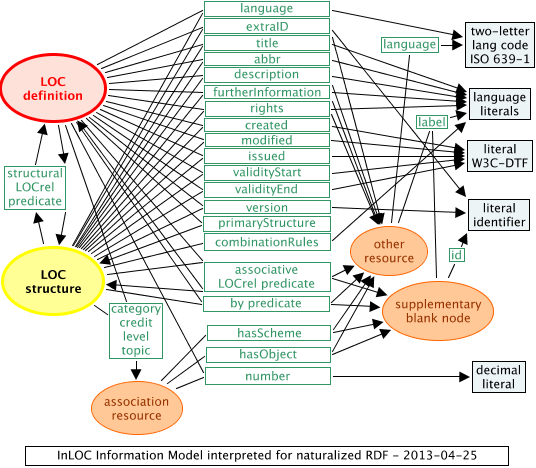
Figure 2: The InLOC information model, as modified for naturalized RDF
In the original information model, the type property of LOCassociation was listed as one of the six values allowed by InLOC. For naturalized RDF, it is the predicate itself that represents the type, either explicitly, or by the predicate being a sub-property of the types LOCrel or by.
Structural LOCrel predicates (e.g. hasLOCpart) only have LOCstructure or LOCdefinition as objects, so these are the simplest cases, and distinguished in Figure 2 by being placed between the LOCstructure and LOCdefinition graphics. Associative LOCrel and by predicates need no further information to specify what is the scheme in the original information model. They are therefore placed in the central column of predicates.
The other kind of associations – category, credit, level and topic, still need their scheme specifying, and may have several kinds of InLOC object. So, they are introduced as an "association triple" with a LOCstructure or LOCdefinition as subject, their own IRI as predicate, and an "association resource" as the triple object. That resource is then the subject of "secondary" triples: a "hasScheme" triple links to whatever represents the scheme, and a "hasObject" triple links to whatever represents the object, similarly to the original information model, and not very different from Figure 1. But, instead of the fixed containers for scheme and object in the information model, RDF offers the opportunity to distinguish:
- another RDF resource, that is, identified by an IRI;
- or a "supplementary" blank node, where there is no IRI defined.
The number predicate has its own triples, with a decimal literal object and two possible kinds of subject:
- a LOCdefinition, for use with hasDefinedLevel;
- the blank node object of a credit or level triple.
This in turn means that each LOCdefinition can be associated with at most one number, which is another restriction to the generality of this naturalized representation. If one LOCdefinition is represented meaningfully with two different numbers, then for naturalized RDF the LOCdefinition would need to be split into two, with different ids.
To compare back with the original UML diagram, the Information Model wiki has a UML diagram for linked data, illustrating a possible way of representing the naturalized RDF model in UML.
In this naturalized RDF approach, one cannot simply create different labels (in the same language) for the same scheme or object, as one can within the XML LOCassociation structure, because there is no easy way of distinguishing different labels (in the same language) for the same scheme or object in different contexts. If there are schemes or objects that have had the same id in an XML binding, but need different labels (in the same language), it will be necessary to give them different ids, or represent them as blank nodes.
Conditions required for naturalized RDF
To summarise, these are the extra constraints that an InLOC representation must conform to, in order that the information is able to be fully represented in InLOC naturalized RDF.
- Every LOCstructure and LOCdefinition must have an IRI as an id.
- Every InLOC subject must be given as a LOCstructure or LOCdefinition.
- A LOCdefinition object of hasDefinedLevel cannot have more than one number.
- Any given scheme or object cannot have more than one label in any given language.
LOC structures and definitions
For the basic information about LOC structures and LOC definitions, both RDF representations introduced above would be the same. Figure 3 here shows the part of the RDF model that is covered in this section.
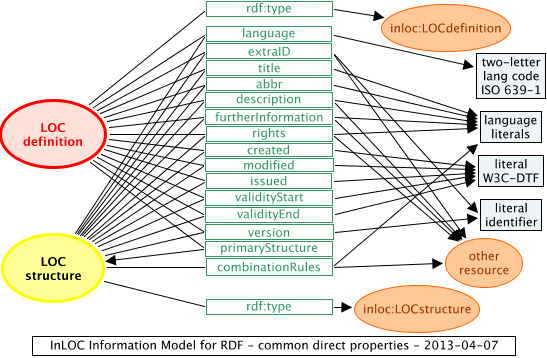
Figure 3: InLOC direct properties represented as RDF
Figure 3 shows the InLOC direct properties as they are represented in RDF – some of them may be classed as "resources" as an alternative to other literals, as already shown in Figure 1, because they can potentially be represented by an IRI.
In addition to the information already shown in Figures 1 and 2, Figure 3 shows triples with predicate "rdf:type", which also natural to any RDF representation – "rdf:type" is abbreviated in Turtle to "a". The IRIs of actual LOC structures or definitions do not indicate which they are – in XML this is done through the tag name. So there must be a triple stating whether each resource in the structure is a LOC structure or a LOC definition. The object of this triple is an IRI – either <http://purl.org/net/inloc/LOCstructure> (same as "inloc:LOCstructure") or <http://purl.org/net/inloc/LOCdefinition> (same as "inloc:LOCdefinition") accordingly.
With the XML binding, the relevant parts here would be as follows, with the Framework as a whole represented by the containing LOC structure, and with sample LOC definitions, which may be placed inside or outside the LOC structure.
<?xml version="1.0" encoding="UTF-8"?> <LOCstructure xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xml="http://www.w3.org/XML/1998/namespace" xmlns="http://purl.org/net/inloc/" xsi:schemaLocation="http://purl.org/net/inloc/ http://purl.org/net/inloc/inloc_schema.xsd" id="http://www.vitae.ac.uk/researchers/uri/vitaerdf" xml:lang="en"> <title>Vitae Researcher Development Framework</title> <abbr>Vitae RDF</abbr> <description> The Researcher Development Framework (RDF) is a major new approach to researcher development, to enhance our capacity to build the UK workforce, develop world-class researchers and build our research base. The RDF is a professional development framework for planning, promoting and supporting the personal, professional and career development of researchers in higher education. It articulates the knowledge, behaviours and attributes of successful researchers and encourages them to realise their potential. </description> <furtherInformation> http://www.vitae.ac.uk/researchers/430901-291181/Researcher-Development-Framework-RDF.html </furtherInformation> <rights>http://www.vitae.ac.uk/researchers/274251/RDF-conditions-of-use.html</rights> <issued>2010</issued> <validityStart>2010</validityStart> <validityEnd>2015</validityEnd> <version>2 April 2011</version> <LOCdefinition id="http://www.vitae.ac.uk/researchers/uri/B"> <title>Personal effectiveness</title> <description> This domain contains the personal qualities, career and self-management skills required to take ownership for and control of professional development. </description> </LOCdefinition> <LOCdefinition id="http://www.vitae.ac.uk/researchers/uri/B2"> <title>Self-management</title> </LOCdefinition> <LOCdefinition id="http://www.vitae.ac.uk/researchers/uri/B2-2"> <title>Commitment to research</title> </LOCdefinition> <LOCdefinition id="http://www.vitae.ac.uk/researchers/uri/B2-2_Ph2"> <description> Evaluates and manages potential distractions. Dedicated: has purposeful and determined focus on developing own research and research credentials. </description> </LOCdefinition> </LOCstructure>
Turtle preamble with prefixes
This initial piece of RDF in Turtle syntax allows the easier reading of the triples following, by defining prefixes. All the following RDF snippets follow the same Turtle syntax, and assuming that all these prefixes have been defined.
## prefixes frequently seen elsewhere @prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> . @prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> . @prefix xsd: <http://www.w3.org/2001/XMLSchema> . ## the main inloc prefix for InLOC concepts @prefix inloc: <http://purl.org/net/inloc/> . ## the prefix used for the particular structure, changes with every different structure @prefix VRDF: <http://www.vitae.ac.uk/researchers/uri/> . # this is only a suggestion at this stage
If the N-Triples syntax is used, there are no prefixes, and all triples occur in their full form, with a full IRI for every subject and predicate.
A LOC structure with its direct properties
LOC structures and LOC definitions, along with their direct properties, are represented simply with triples, and there is no difference between the different styles of RDF.
Here is the main structure in this example:
## the main structure VRDF:vitaerdf a inloc:LOCstructure . VRDF:vitaerdf inloc:language "en" . VRDF:vitaerdf inloc:title "Vitae Researcher Development Framework" . VRDF:vitaerdf inloc:abbr "VitaeRDF" . VRDF:vitaerdf inloc:description '''The Researcher Development Framework (RDF) is a major new approach to researcher development, to enhance our capacity to build the UK workforce, develop world-class researchers and build our research base. The RDF is a professional development framework for planning, promoting and supporting the personal, professional and career development of researchers in higher education. It articulates the knowledge, behaviours and attributes of successful researchers and encourages them to realise their potential.''' . VRDF:vitaerdf inloc:furtherInformation <http://www.vitae.ac.uk/researchers/430901-291181/Researcher-Development-Framework-RDF.html> . VRDF:vitaerdf inloc:rights <http://www.vitae.ac.uk/researchers/274251/RDF-conditions-of-use.html> . VRDF:vitaerdf inloc:issued "2010" . VRDF:vitaerdf inloc:validityStart "2010" . VRDF:vitaerdf inloc:validityEnd "2015" . VRDF:vitaerdf inloc:version "2 April 2011" .
Note that the resource "VRDF:vitaerdf" is stated to be a LOC structure.
LOC definitions
LOC definitions are represented a similar way. Naturally, instead of being an "inloc:LOCstructure" it is an "inloc:LOCdefinition". Most of the direct properties are here, as expected in most cases, inherited from the LOC structure, so the only direct properties needed are the title and/or description.
Here is one of the "Domains":
VRDF:B a inloc:LOCdefinition . VRDF:B inloc:title "Personal effectiveness" . VRDF:B inloc:description '''This domain contains the personal qualities, career and self-management skills required to take ownership for and control of professional development.''' .
Every domain contains sub-domains. One of these is
VRDF:B2 a inloc:LOCdefinition . VRDF:B2 inloc:title "Self-management" .
Each sub-domain contains descriptors, e.g.
VRDF:B2-2 a inloc:LOCdefinition . VRDF:B2-2 inloc:title "Commitment to research" .
Finally, each descriptor has several phases of development, somewhat like levels in other frameworks. One of these is:
VRDF:B2-2_Ph2 a inloc:LOCdefinition . VRDF:B2-2_Ph2 inloc:description '''Evaluates and manages potential distractions. Dedicated: has purposeful and determined focus on developing own research and research credentials.''' .
Graph for LOC structure and definitions
All the above triples are represented here graphically in Figure 4.
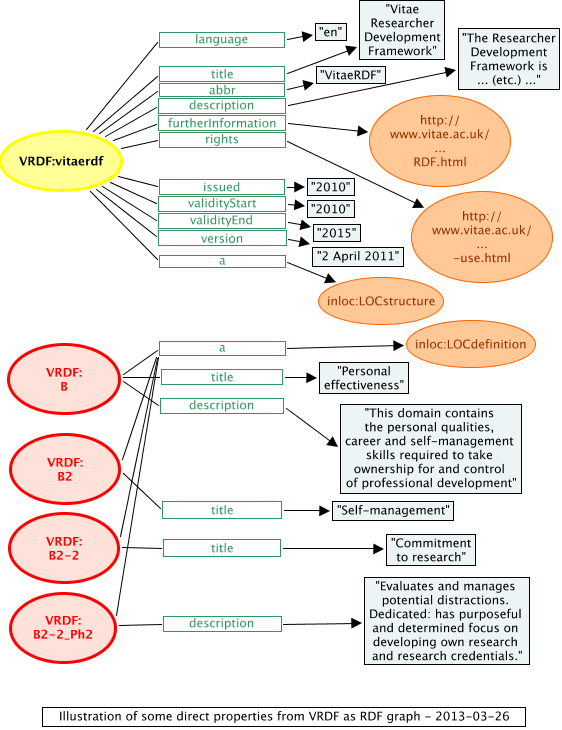
Figure 4: the same triples from the VRDF represented graphically
Figure 4 excludes triples representing LOC associations.
LOC associations
The six different types of LOC association have slightly different semantics, and therefore need illustrating separately. First illustrated here is the "by" type, which could be seen as the easiest; then the "LOCrel" type, followed by the rest of the LOC association types: "category"; "credit"; "level" and "topic".
All the associations are represented quite differently in the two RDF styles.
- The style following the original model mirrors the XML LOC association structure. This involves several RDF nodes, which are given in this illustration as blank nodes. The initial triple has the predicate comprisesAssociation.
- In contrast, the style naturalizing RDF does not represent the association directly, but conceives of the association as being represented by an initial "association triple", with the association's subject, scheme (as RDF predicate), and object. In most cases the object is represented by its IRI id, or a literal. The exception is for LOC associations of type credit, where a blank node must be used for the object, though differently from from when represented RDF following the original model.
A "by" association
The "by" associations are those that give the author, publisher, etc., usually of a LOC structure. It is also possible to give these properties of a LOC definition, when represented separately from its "home" LOC structure.
The example here gives the publisher of the whole framework. The relevant XML would be as follows. This snippet would be contained directly within the XML <LOCstructure> element.
<LOCassociation type="http://purl.org/net/inloc/by"> <subject id="http://www.vitae.ac.uk/researchers/uri/vitaerdf"></subject> <scheme id="http://purl.org/net/inloc/publisher"></scheme> <object id="http://www.crac.org.uk/#id"> <label>CRAC: The Career Development Organisation</label> </object> </LOCassociation>
RDF graph following original model
If a graph were to be drawn following the original information model, it would look like Figure 5.
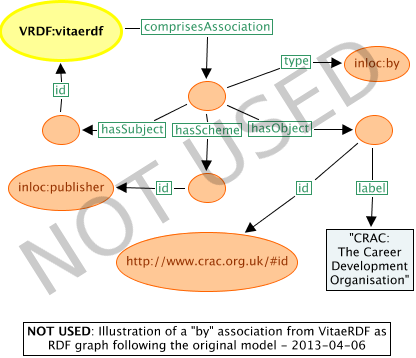
Figure 5: RDF graph for a "by" association from VRDF, following the original model – NOT USED.
This is hard to follow, which justifies this representation not being used for the InLOC RDF binding.
Naturalized RDF
As the naturalized RDF discards the LOCassociation node, any IRI that might have been given for the LOC association (in an XML binding) will be discarded, as there is no place for it in the naturalized RDF representation. Instead of representing the type of LOCassociation as an IRI object of an id predicate, it is represented by the IRI being used as the actual predicate of the main triple.
The basic form is this.
VRDF:vitaerdf inloc:publisher <http://www.crac.org.uk/#id> . <http://www.crac.org.uk/#id> inloc:label "CRAC: The Career Development Organisation" .
There are some optional extras that can be added with extra triples:
- RDF provides an easy way to add on a language tag to any literal text value.
<http://www.crac.org.uk/#id> inloc:label "CRAC: The Career Development Organisation"@en .
Multiple labels could be added, each with their own language.
- From an ontological point of view, publisher is a sub-property of by. If desired, this can be represented explicitly as
inloc:publisher rdfs:subPropertyOf inloc:by .
Figure 6 shows the the graph for this naturalized representation.
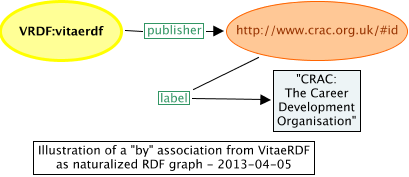
Figure 6: naturalized RDF graph for a "by" association within VRDF
Other "by" relations
Other similar relations can be represented in the same way, simply by replacing "publisher" with "creator", "contributor" or "rightsHolder" as appropriate, and changing the id and label of the agent.
A "LOCrel" association with no number
The "LOCrel" type of LOC association serves to relate together LOC structures and LOC definitions, making the structure of the LOC structure explicit. The example given here is the framework as a whole relating to one of its main parts, that is, one of the "domains".
<LOCassociation type="http://purl.org/net/inloc/LOCrel"> <subject id="http://www.vitae.ac.uk/researchers/uri/vitaerdf"></subject> <scheme id="http://purl.org/net/inloc/hasLOCpart"></scheme> <object id="http://www.vitae.ac.uk/researchers/uri/B"></object> </LOCassociation>
Graph for RDF following original model
Figure 7 shows an RDF graph for two of these relationships from the VRDF as it would look were the original information model to be followed closely. It is relatively very difficult to follow. This is further justification for the InLOC RDF binding not following the original information model closely, but changing it to a naturalized version.
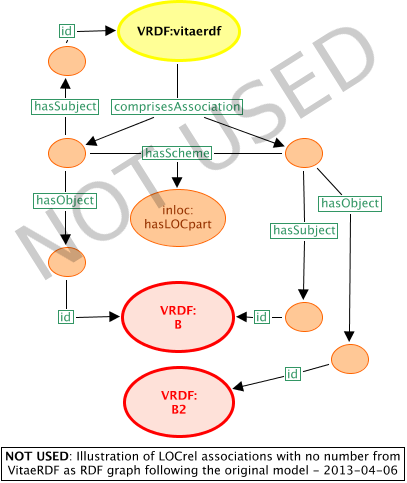
Figure 7: RDF graph following the original model, showing the necessary complexity of this style of representation – NOT USED.
Naturalized RDF
This is done similarly to "by" LOC associations. Instead of representing the type of LOCassociation as an IRI object of an id predicate, it is represented by the IRI being used as the actual predicate of the main triple. There is no need for any blank nodes. The single triple is clear and self-explanatory, being a triple that directly relates the relevant LOC structure and LOC definition. InLOC calls this an "association triple".
VRDF:vitaerdf inloc:hasLOCpart VRDF:B .
As in the previous example, the fact that this LOCassociation has type LOCrel can be deduced from the use of the scheme.id "hasLOCpart". But this could also be represented explicitly as
inloc:hasLOCpart rdfs:subPropertyOf inloc:LOCrel .
Whether to include this or not would depend on whether the receiving system knows the ontology.
The RDF graph for the naturalized style, Figure 8, is relatively very straightforward indeed.
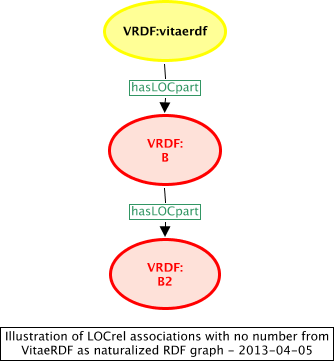
Figure 8: naturalized RDF graph for two structural relations in the VRDF
In view of the much greater simplicity of the naturalized RDF graph, only this is illustrated in subsequent examples.
A "LOCrel" association with a number
The relationship hasDefinedLevel requires the use of a number, representing a numeric value for the defined level, in the sense that a greater number means greater competence, etc. The example here relates one of the VRDF "descriptors" to one of its "phases".
<LOCassociation type="http://purl.org/net/inloc/LOCrel"> <subject id="http://www.vitae.ac.uk/researchers/uri/B2-2"></subject> <scheme id="http://purl.org/net/inloc/hasDefinedLevel"></scheme> <object id="http://www.vitae.ac.uk/researchers/uri/B2-2_Ph2"></object> <number>2</number> </LOCassociation>
Naturalized RDF
In this case, for the naturalized RDF representation, the number moves from being a property of the LOC association to being a property of the object. This depends on there being at most one number associated with each distinct object. In this case, the object can only be a LOCdefinition.
VRDF:B2-2 inloc:hasDefinedLevel VRDF:B2-2_Ph2 . VRDF:B2-2_Ph2 inloc:number "2"^^xsd:decimal .
This may not be quite so immediately clear to a reader, but it is certainly has the minimum number of triples needed to convey the information. The restriction about each object having at most one number comes from the fact that triples are essentially separate, and that if a further triple was given with VRDF:B2-2_Ph2 having a number other that "2" this would cause ambiguity that could not be resolved.
Figure 9 gives the graph for the naturalized RDF.
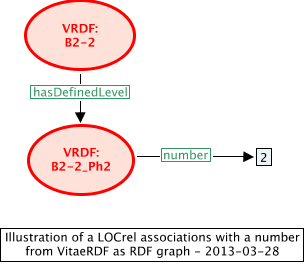
Figure 9: naturalized RDF graph for a level definition in the VRDF
Some "category" associations
Vitae does not provide any external categorisation for any elements of their RDF. However, for some purposes it might be useful to know explicitly where any given LOC definition fits into the Vitae RDF scheme of things. So far, from the RDF given, it is only possible to work out whether a LOC definition is a "domain", a "sub-domain", a "descriptor" or a "phase" from the context of how many links it is from the framework as a whole. The framework as a whole is directly linked, through "hasLOCpart", to each "domain", the domains are directly linked to the subdomains, and so on. But there could be a category scheme that allows people to define directly what kind of LOC definition it is, in Vitae terms.
Reusing the example material from above, this example gives the Vitae category of the domain B, which is, of course, a "Domain" in Vitae's terms. A category file has been created to illustrate how the IRIs associated with category schemes and terms can work most simply in terms of the W3C concept of "Cool URIs for the Semantic Web" and static page on the web.
<LOCassociation type="http://purl.org/net/inloc/category"> <subject id="http://www.vitae.ac.uk/researchers/uri/B"></subject> <scheme id="http://www.simongrant.org/InLOC/Vitae_categories#"> <label>Vitae object category</label> </scheme> <object id="http://www.simongrant.org/InLOC/Vitae_categories#domain"> <label>Domain</label> </object> </LOCassociation>
Naturalized RDF
With IRIs for scheme and object
The first version of this assumes that both the category scheme and object are given as full IRIs.
VRDF:B inloc:category _:blank10 . _:blank10 inloc:hasScheme <http://www.simongrant.org/InLOC/Vitae_categories#> . _:blank10 inloc:hasObject <http://www.simongrant.org/InLOC/Vitae_categories#domain> . <http://www.simongrant.org/InLOC/Vitae_categories#> inloc:label "Vitae object class" . <http://www.simongrant.org/InLOC/Vitae_categories#domain> inloc:label "Domain" .
With a blank node for the object
If there is a non-IRI id, an extra blank node must be defined, and the (non-IRI) id given alongside the labels. This example is for a "Descriptor".
VRDF:B2-2 inloc:category _:blank13 . _:blank13 inloc:hasScheme <http://www.simongrant.org/InLOC/Vitae_categories#> . _:blank13 inloc:hasObject _:blank131 . _:blank131 inloc:id "descriptor" . _:blank131 inloc:label "Descriptor"@en . _:blank131 inloc:label "Descripteur"@fr .
Graph for naturalized RDF
Figure 10 gives two different variants for representing category relation examples from the VRDF, depending on different assumptions about the identifiers that are desired. This mirrors the examples above.
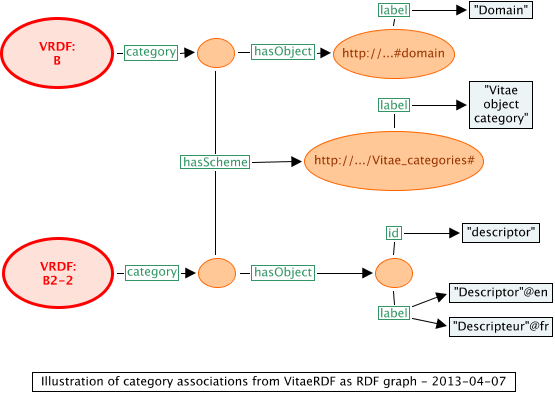
Figure 10: naturalized RDF graph for category relations in the VRDF
A "credit" association
The Vitae RDF is not the kind of framework that naturally has credits attached.
However, one can perhaps imagine that someone could base a funded course on the VDRF, with perhaps some of the VRDF phase definitions as intended learning outcomes of the course. Imagine that the Phase 2 descriptor was the learning outcome, and that it was associated with 10 ECTS credits. Being part of doctoral or postdoctoral work, it would seem natural to assign the highest ECTS level, called the "third cycle", to this. A footnote in the ECTS users guide states:
There is no consensus on the usefulness of credits for the third cycle, but technically it is possible to attach credits to any cycle.
The CEN Workshop Agreement from January 2010 – CWA 16077, "Educational Credit Information Model" – provides a model for educational credit information. This is an adaptation of a fragment of one of the examples given in CWA 16077, to fit the current example:
<scheme>http://purl.org/net/cm/terms/ECTS</scheme> <scheme xsi:type=”ex:sd” xml:lang=”en”>European Credit Transfer and Accumulation System</scheme> <level>http://purl.org/net/cm/terms/ECTS#3</level> <level xsi:type=”ex:exlevel” xml:lang=”en”>Third cycle</level> <value>10</value>
Represented as InLOC XML, this could be given as
<LOCassociation type="http://purl.org/net/inloc/credit"> <subject id="http://www.vitae.ac.uk/researchers/uri/B2-2_Ph2"></subject> <scheme id="http://purl.org/net/cm/terms/ECTS"> <label xml:lang="en">European Credit Transfer and Accumulation System</label> </scheme> <object id="http://purl.org/net/cm/terms/ECTS#3"> <label xml:lang="en">Third cycle</label> </object> <number>10</number> </LOCassociation>
Naturalized RDF
VRDF:B2-2_Ph2 inloc:credit _:blank20 . _:blank20 inloc:hasScheme _:blank21 . _:blank20 inloc:hasObject _:blank22 . _:blank20 inloc:number "10"^^xsd:decimal . _:blank21 inloc:label "ECTS" . _:blank22 inloc:label "Third cycle"@en . _:blank22 inloc:label "troisième cycle"@fr .
Credit assignment must have a credit scheme, so the hasScheme triple is mandatory. But it is possible for a credit scheme to have no levels, in which case the hasObject triple and any related labels would simply be left out, with no adverse consequences.
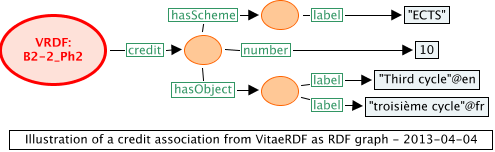
Figure 11: naturalized RDF graph for an imagined credit association as if in the VRDF
A "level" association
The "level" association is used to map LOC structures or definitions to external levels.
The overall "stages" of the VRDF do look as if they might be mapped to other level schemes. Though the Vitae RDF doesn't actually do this, one could speculate that Phase 2 of "Commitment to research" might be associated with EQF level 5. It is not clear whether all the descriptors for the same phase belong to the same EQF level. If they did, there would be a case for making more of the Phases as substantive entities; making them into LOC definitions in their own right, as is done in the e-CF example, given with the XML binding.
<LOCassociation type="http://purl.org/net/inloc/level"> <subject id="http://www.vitae.ac.uk/researchers/uri/B2-2_Ph2"></subject> <scheme id=""> <label>EQF</label> </scheme> <object id="eqf#5"> <label>EQF Competence Level 5</label> </object> <number>5</number> </LOCassociation>
Naturalized RDF
The EQF gives separate descriptors of levels for knowledge, skill and competence. In this example, the labelling assumes that "eqf#5" just refers to the competence level, rather than the other two. If any knowledge or skill levels appear in the same framework, the ID should be changed accordingly, for instance in this case to "eqfc#5" as opposed to "eqfk#5" or "eqfs#5". In the naturalized RDF, there must only be one label for each separate explicit IRI.
To illustrate one aspect of best practice, here, the object is given an IRI as well.
VRDF:B2-2_Ph2 inloc:level _:blank30 . _:blank30 inloc:hasScheme <http://purl.cen.eu/ids/eqf> . _:blank30 inloc:hasObject <http://purl.cen.eu/ids/eqf#5> . _:blank30 inloc:number "5"^^xsd:decimal . <http://purl.cen.eu/ids/eqf> inloc:label "EQF" . <http://purl.cen.eu/ids/eqf#5> inloc:label "EQF Competence Level 5" .
Figure 12, in contrast to Figure 11, shows the use of RDF IRIs, instead of using extra blank nodes.
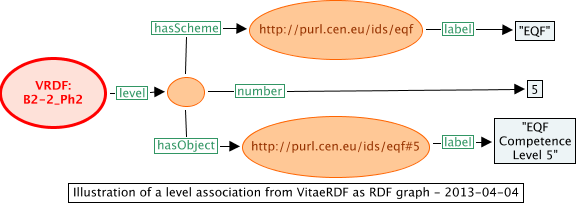
Figure 12: naturalized RDF graph for an imagined level association as if in the VRDF
A "topic" association
The VITAE RDF doesn't have any explicit topics. (The term "subject" is sometimes used as a synonym for "topic", but here it would risk confusion with the subject of a triple.) One could, however, cross-reference some parts of the structure to, e.g., bibliographic classifications. Thus, perhaps, Vitae RDF B3, "Professional and career development", could be catalogued under UDC 377, "Specialized instruction. Vocational, technical, professional training. Vocational colleges, institutes. Polytechnics." It is not clear what the best IRI for the UDC system itself is. The Wikipedia article http://en.wikipedia.org/wiki/Universal_Decimal_Classification is unambiguously about it, but probably better is the IRI proposed by DCMI: http://purl.org/dc/terms/UDC, which is a "vocabulary encoding scheme". Though the method given here is not how DCMI envisage the use of their vocabulary encoding scheme, it does seem a reasonable approach, not subject to any ambiguity.
The decimal classification number itself is an identifier relative to the classification scheme, not universally unique, and not an IRI as such.
This is not wholly satisfactory, as it fails to include the version number or date of the bibliographic classification scheme. Ideally, an IRI for UDC would include at least one of these, to prevent ambiguity.
<LOCassociation type="http://purl.org/net/inloc/topic"> <subject id="http://www.vitae.ac.uk/researchers/uri/B3"></subject> <scheme id="http://purl.org/dc/terms/UDC"> <label>Universal Decimal Classification</label> </scheme> <object id="377"></object> </LOCassociation>
Naturalized RDF
The IRI for the UDC system is used as the scheme.
VRDF:B3 inloc:topic :_blank40 . _:blank40 hasScheme <http://purl.org/dc/terms/UDC> . <http://purl.org/dc/terms/UDC> inloc:label "Universal Decimal Classification" . _:blank40 hasObject _:blank41 . _:blank41 inloc:id "377" .
In this case, as there is a non-IRI id for the object, a blank node is needed for the object.
Figure 13 shows how a topic association might be represented in naturalized RDF.
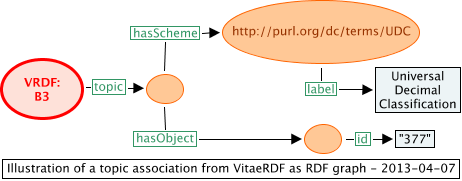
Figure 13: naturalized RDF graph for an imagined topic association as if in the VRDF
Graph for LOC associations
A selection of the above naturalized RDF triples are represented here graphically in Figure 14. This figure introduces no new kinds of triples, but just puts together all the kinds that have been illustrated above.
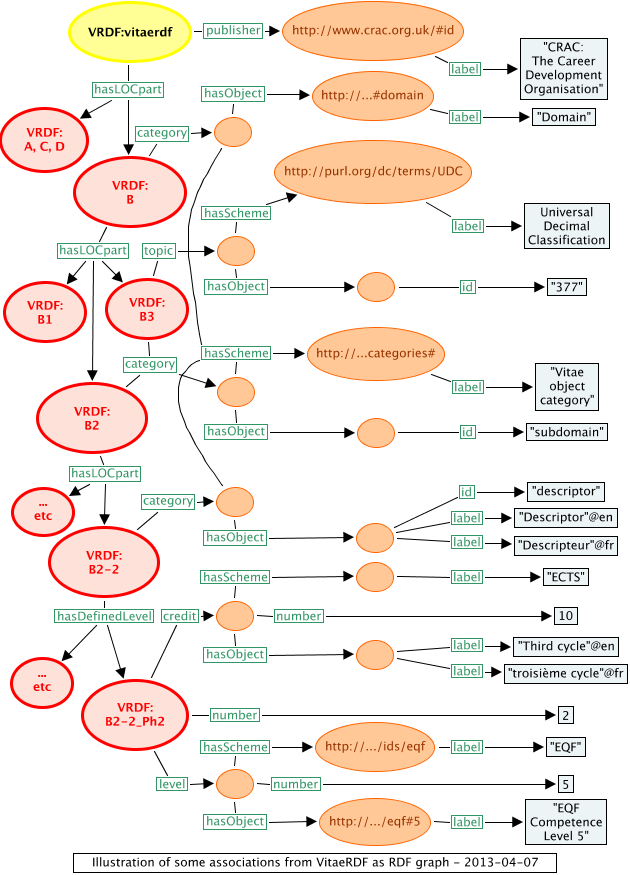
Figure 14: a selection of association triples from VRDF represented graphically
Figure 14 excludes triples representing direct properties of LOC structures and definitions – these are illustrated in Figure 4.
Other considerations
Sub-structures
The InLOC Information Model allows sub-structures of a LOCstructure to exist. This allows the inclusion of one LOCstructure, complete with its LOCdefinitions and LOCassociations, inside another LOCstructure, while retaining its identity.
However, in RDF this is not possible in the same way. Many systems using RDF are able to distinguish distinguish separate RDF graphs, but Turtle and N-Triples do not have the concept of a graph within a file. Therefore, for simple systems and tools it is recommended that only one LOCstructure is present in any one InLOC RDF file.
It is still possible to have sub-structures represented in RDF, but it is not possible to represent a LOCassociation as being inside or outside a sub-structure. Therefore, if sub-structures are used, the RDF will be equivalent to an XML structure where all the LOCassociations are contained within the outermost LOCstructure, and not within any of the sub-structures.
Other information that could be added in RDF
Adding extra information that is not described here in RDF format does not normally disrupt the existing information. So, for example, there may be agreed a way of adding an ISBN to a document. This could be done directly, simply introducing an extra triple. The subject IRI would be, as before, "VRDF:vitaerdf", and the object could be given as the IRI "urn:isbn:978-1-906774-18-9". The predicate could be anything agreed that represents the ISBN property.
Any extra properties added in this way, which are not specified by InLOC, may be ignored or discarded by any receiving system.
Variant predicate IRIs
The tables describing the InLOC properties and relationships, to be found through the InLOC properties page, include various equivalent IRIs to the ones defined for InLOC. While in XML it takes more effort to process these alternative terms, in RDF it is very simply a matter of specifying them as equivalent, and accepting them as input to any InLOC compliant system. This could be done with a simple pre-processing step of substituting the InLOC terms for their equivalent terms. Alternatively, any output or export could, according to preference, use any of the other defined IRIs instead of the InLOC ones.
Unexpected literal values
Following the practice accomodated by schema.org, it may be that triples expecting an RDF object of one of the classes labelled "other resource" or "supplementary blank node" (in Figure 2) may instead be found to have a literal as RDF object. This could be for associative "LOCrel" predicates, "by" predicates, "hasScheme" or "hasObject" predicates. If an unexpected literal value is encountered in these places, it should be interpreted as if there were a supplementary blank node, and that node had a label property with the given literal as its value.
Use of the naturalized RDF binding
As can be seen from the examples above, the naturalized style of RDF appears greatly preferable to a style following the original model, from the points of view of compactness, ease of understanding, and ease of query formulation. Therefore, this is the proposed binding.
RDFS ontology for naturalized RDF binding
This ontology using RDF Schema terms is given in Turtle format. It has not been rigorously checked, and may be altered in response to the feedback from any implementation that uses it.
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> . @prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> . @prefix inloc: <http://purl.org/net/inloc/> . ### ### InLOC classes ### inloc:LOC a rdfs:Class . # abstract inloc:LOCdefinition a rdfs:Class . inloc:LOCstructure a rdfs:Class . inloc:AssociationResource a rdfs:Class . # may be blank # the following class is not in any of the diagrams inloc:Numberable a rdfs:Class . # artificial superclass of LOCdefinition and AssociationResource # we don't know what rdf:type the other resources might be ### ### InLOC properties ### # the direct properties defined in the information model inloc:abbr a rdf:Property . inloc:combinationRules a rdf:Property . # inloc:comprisesAssociation a rdf:Property . not in RDF model inloc:extraID a rdf:Property . inloc:furtherInformation a rdf:Property . inloc:hasObject a rdf:Property . inloc:hasScheme a rdf:Property . inloc:number a rdf:Property . inloc:primaryStructure a rdf:Property . inloc:validityStart a rdf:Property . inloc:validityEnd a rdf:Property . inloc:version a rdf:Property . inloc:created a rdf:Property . inloc:description a rdf:Property . inloc:id a rdf:Property . inloc:issued a rdf:Property . inloc:label a rdf:Property . inloc:language a rdf:Property . inloc:modified a rdf:Property . inloc:rights a rdf:Property . inloc:title a rdf:Property . # the relationships defined in the information model inloc:closeMatch a rdf:Property . inloc:exactMatch a rdf:Property . inloc:hasDefinedLevel a rdf:Property . inloc:hasExample a rdf:Property . inloc:hasLOCpart a rdf:Property . inloc:hasNecessaryPart a rdf:Property . inloc:hasOptionalPart a rdf:Property . inloc:hasPreRequisite a rdf:Property . inloc:isDefinedLevelOf a rdf:Property . inloc:isExampleOf a rdf:Property . inloc:isLOCpartOf a rdf:Property . inloc:isNecessaryPartOf a rdf:Property . inloc:isOptionalPartOf a rdf:Property . inloc:isPreRequisiteOf a rdf:Property . inloc:isReplacedBy a rdf:Property . inloc:related a rdf:Property . inloc:replaces a rdf:Property . # the "by" predicates, in the model but not as properties inloc:contributor a rdf:Property . inloc:creator a rdf:Property . inloc:publisher a rdf:Property . inloc:rightsHolder a rdf:Property . ### ### properties not in the model as properties ### # the association types transferred from the information model "type" inloc:LOCrel a rdf:Property . # see below inloc:by a rdf:Property . # contributor; creator; publisher; rightsHolder inloc:category a rdf:Property . inloc:credit a rdf:Property . inloc:level a rdf:Property . inloc:topic a rdf:Property . # convenience super-properties not appearing at all in the original information model inloc:date a rdf:Property . # 5 direct properties as dcterms date inloc:directProperty a rdf:Property . # 5 other literal direct properties inloc:hasCompoundProperty a rdf:Property . # category; credit; level; topic inloc:isAssociatedWith a rdf:Property . # hasCompoundProperty; LOCrel; by ### ### RDFS statements ### ### sub-class relationships inloc:LOCdefinition rdfs:subClassOf inloc:LOC . inloc:LOCstructure rdfs:subClassOf inloc:LOC . inloc:LOCdefinition rdfs:subClassOf inloc:Numberable . inloc:AssociationResource rdfs:subClassOf inloc:Numberable . ### ### relationships that are sub-properties ### # 4 sub-properties of hasLOCpart inloc:hasDefinedLevel rdfs:subPropertyOf inloc:hasLOCpart . inloc:hasExample rdfs:subPropertyOf inloc:hasLOCpart . inloc:hasNecessaryPart rdfs:subPropertyOf inloc:hasLOCpart . inloc:hasOptionalPart rdfs:subPropertyOf inloc:hasLOCpart . # the 4 (inverse) sub-properties of isLOCpartOf inloc:isDefinedLevelOf rdfs:subPropertyOf inloc:isLOCpartOf . inloc:isExampleOf rdfs:subPropertyOf inloc:isLOCpartOf . inloc:isNecessaryPartOf rdfs:subPropertyOf inloc:isLOCpartOf . inloc:isOptionalPartOf rdfs:subPropertyOf inloc:isLOCpartOf . # one other natural sub-property inloc:exactMatch rdfs:subPropertyOf inloc:closeMatch . # the rest of the defined relationship have LOCrel as super-property inloc:closeMatch rdfs:subPropertyOf inloc:LOCrel . inloc:hasLOCpart rdfs:subPropertyOf inloc:LOCrel . inloc:hasPreRequisite rdfs:subPropertyOf inloc:LOCrel . inloc:isLOCpartOf rdfs:subPropertyOf inloc:LOCrel . inloc:isPreRequisiteOf rdfs:subPropertyOf inloc:LOCrel . inloc:isReplacedBy rdfs:subPropertyOf inloc:LOCrel . inloc:related rdfs:subPropertyOf inloc:LOCrel . inloc:replaces rdfs:subPropertyOf inloc:LOCrel . # the 4 sub-properties of "by" inloc:contributor rdfs:subPropertyOf inloc:by . inloc:creator rdfs:subPropertyOf inloc:by . inloc:publisher rdfs:subPropertyOf inloc:by . inloc:rightsHolder rdfs:subPropertyOf inloc:by . # new super-property hasCompoundProperty inloc:category rdfs:subPropertyOf inloc:hasCompoundProperty . inloc:credit rdfs:subPropertyOf inloc:hasCompoundProperty . inloc:level rdfs:subPropertyOf inloc:hasCompoundProperty . inloc:topic rdfs:subPropertyOf inloc:hasCompoundProperty . # new super-property isAssociatedWith inloc:by rdfs:subPropertyOf inloc:isAssociatedWith . inloc:LOCrel rdfs:subPropertyOf inloc:isAssociatedWith . inloc:hasCompoundProperty rdfs:subPropertyOf inloc:isAssociatedWith . ### ### direct property sub-properties ### # sub-properties of rdfs:label, which has rdfs:range rdfs:literal inloc:abbr rdfs:subPropertyOf rdfs:label . inloc:label rdfs:subPropertyOf rdfs:label . inloc:title rdfs:subPropertyOf rdfs:label . # 5 sub-properties of convenience super-property date inloc:created rdfs:subPropertyOf inloc:date . inloc:modified rdfs:subPropertyOf inloc:date . inloc:issued rdfs:subPropertyOf inloc:date . inloc:validityEnd rdfs:subPropertyOf inloc:date . inloc:validityStart rdfs:subPropertyOf inloc:date . # directProperty the general super-property with LOC domain and literal range inloc:extraID rdfs:subPropertyOf inloc:directProperty . inloc:furtherInformation rdfs:subPropertyOf inloc:directProperty . inloc:version rdfs:subPropertyOf inloc:directProperty . inloc:description rdfs:subPropertyOf inloc:directProperty . inloc:rights rdfs:subPropertyOf inloc:directProperty . inloc:date rdfs:subPropertyOf inloc:directProperty . ### ### range and domain statements... ### ### Ranges and domains of sub-properties are subsets ### of the range and domain of the super-property. ### Do they still have to be spelled out? ### Here is is assumed not. ### inloc:directProperty rdfs:domain inloc:LOC . inloc:directProperty rdfs:range rdfs:Literal . inloc:combinationRules rdfs:domain inloc:LOCstructure . inloc:combinationRules rdfs:range rdfs:Literal . inloc:primaryStructure rdfs:domain inloc:LOCdefinition . inloc:primaryStructure rdfs:range inloc:LOCstructure . inloc:id rdfs:range rdfs:Literal . inloc:isAssociatedWith rdfs:domain inloc:LOC . inloc:hasLOCpart rdfs:range inloc:LOC . inloc:isLOCpartOf rdfs:range inloc:LOC . inloc:hasCompoundProperty rdfs:range inloc:AssociationResource . # domain of hasCompoundProperty inferred through isAssociatedWith inloc:hasScheme rdfs:domain inloc:AssociationResource . inloc:hasObject rdfs:domain inloc:AssociationResource . inloc:number rdfs:domain inloc:Numberable . inloc:number rdfs:range rdfs:Literal . ### ### not needed to document the default range rdfs:Resource, so commented out ### # inloc:by rdfs:range rdfs:Resource . # inloc:hasScheme rdfs:range rdfs:Resource . # inloc:hasObject rdfs:range rdfs:Resource . # inloc:isAssociatedWith rdfs:range inloc:Resource .
How to convert InLOC naturalized RDF triples to XML
Here is a description of the process for converting InLOC naturalized RDF triples to InLOC XML, where there is exactly one LOC structure. It may be used as the basis for creating software to do this automatically.
There are six types of statements that may occur in InLOC naturalized RDF:
- directives (in Turtle but not N-Triples representations);
- three kinds of triples with LOCstructures or LOCdefinitions as subjects
- "LOC" triples, with predicate "a" (in Turtle) or "rdf:type" (in N-Triples), declaring a LOCstructure or LOCdefinition;
- "direct" triples, with direct properties as predicates and literal or other resource objects, which must be represented in the correct order within the relevant LOCstructure or LOCdefinition XML;
- "association" triples, with the other property predicates defined by InLOC, signifying a LOCassociation;
- "secondary" triples, having as subject an association resource, and as predicate "inloc:hasScheme" or "inloc:hasObject" or "inloc:number";
- "supplementary" triples, with predicates "inloc:label", "inloc:id", representing information for InLOC scheme and object ("inloc:id" is just to preserve non-IRI identifiers).
Any algorithm needs to keep a record of which triples have been "processed". Triples that may be processed more than once are those with "supplementary" predicates. All other triples should be processed only once. The algorithm should stop when all triples have been processed.
To generate InLOC XML, the first step is to find the identifier of the main LOCstructure. Then:
- see if the LOC structure has a language (default language);
- create the LOCstructure XML start tag;
- next, process direct properties of this LOCstructure, outputting them in the correct order;
- then deal with the remaining triples;
- lastly, when all triples have been processed, output the XML end tag for the main LOCstructure.
To process the remaining triples involves stepping through them, passing over ones that do not initiate any LOCstructure or LOCdefinition or LOCassociation, until the end, picking up other ones as part of processing these. The order of processing can be varied, to suit any particular view on the best ordering for these elements within the overall LOCstructure.
A "LOC" triple initiates the output of a LOCstructure or LOCdefinition. A LOC triple is processed together with all "direct" triples with the same subject. The XML for the LOCstructure or LOCdefinition must output the direct properties in the right order.
A consequence of this is that all "direct" triples must have a subject that is identified as a LOCstructure or a LOCdefinition. Any other "direct" triple is not a proper part of an InLOC graph.
An "association" triple initiates the output of a LOCassociation XML element. An association triple is processed together with all "secondary" triples whose subjects are the same as the object of the association triple (whether that is an identified resource or a blank node), and also any "supplementary" triples whose subject is the same as the object of those secondary triples. As noted above, "supplementary" triples with non-blank subjects may be processed more than once. Blank nodes are naturally taken into account just the same as resources with IRIs. Note that, in the XML binding, a LOCassociation must have a subject, a scheme and an object. If there is no hasObject triple alongside a hasScheme triple, an empty XML object must be generated (e.g. "<object />").
Following these rules alone, it is possible that some "direct", "supplementary" or "secondary" triples are not processed, as their subjects cannot be found as appropriate predicates or objects in other triples. Any validation process for InLOC RDF, and any conversion process from InLOC RDF to InLOC XML, should warn of the occurrence of any such triples.
Using all the relevant identified triples, a clear algorithm for generating the XML will be given for each each type of LOCassociation.